A concise document based database is designed and created for the flags of the countries across the globe in which textual, numeric and image data are stored.
Motivation
We have embarked on a journey to learn more about flags and what they represent. In the previous post, we preprocessed the images which store the graphical representations. In this one we proceed one step forward in the data analysis pipeline. The raw notebook can be found here.
Database design
Current data structure
The database, flags as it stands now:
mg_client = pymongo.MongoClient("mongodb://localhost:27017/")
print(mg_client.list_database_names())
['admin', 'config', 'flags', 'local']
consists of a single collection, raw_countries:
db_flag = mg_client["flags"]
print(db_flag.list_collection_names())
['countries', 'flags', 'raw_countries']
in which each document lists the attributes of a particular country:
cl_raw_countries = db_flag["raw_countries"]
cl_raw_countries.find_one({})
{'_id': ObjectId('5cb05096351ab07c5454114d'),
'adapted': 2004,
'path': 'C:\\Users\\hornu\\OneDrive\\Documents\\repos\\flags\\data\\clean-data\\images\\afghanistan.png',
'code': 'AF',
'religion': 'ISLAM',
'continent': 'ASIA',
'founded': 9999,
'independent': 1823,
'neighbours': ['CN', 'IR', 'PK', 'TJ', 'TM', 'UZ'],
'name': 'AFGHANISTAN'}
The fields are either pertaining to the country itself:
name: name of the countrycode: two-letter iso code of the countryfounded: year in which the country or its ancestor was founded. 9999 stands for missing datum.independent: year in which the country became independentreligion: predominant religion in the countrycontinent: continent on which the major landmass of the country situatedneighbours: the two letter iso codes of its neighbours
or to its flag:
adapted: year in which the current flag was introducedpath: path to thepngimage of the flag in local store
Design goals
We wish to store these pieces of information in a more orderly fashion. The fields relevant to the country should be contained in a document separated from those relevant to the flag itself. Two collections will thus be created:
countriesandflags
Country document
A country document will have three main fields
_id: unique idcode: two-letter iso code of the countryflag: id of the associated flag documentdata: all other fieldsname: name of the countryfounded: …independent: …adapted: …continent: …religion: …neighbours: …
The country codes of the neighbours list will be replaced by the list of the _id-s of the respective country documents. This implies the collection must be built in two passes.
Flag document
The flags are stored in a different collection. The schema of a document is the following:
_id: unique idcode: two letter country codedata: information on the flagcolours: a dictionary in which the flag’s constituent colours are listed along with their weightsdimensions: a dictionary of height and widthcanvas: the flag itself
We wish to keep this document as sleek as possible. Therefore only the canvas, some precomputed statitics and the human readable country codes are included in it.
Implementation
We set out to implement all the transformations that are required to create the new database.
Flags
The main issue is to find an efficient format for storing the canvas of the flag. We went at great length to rid the flag of spurious colours, therefore any lossy compression is out of question.
Compressing the flag
The cleaned image is a 3D uint8 numpy array. Let us assume an average flag has $500 \cot 1000$ pixels. Each pixel consists of three meaningful channels (R, G, B). It is then represented in the memory as an array of of size $500 \cdot 1000 \cdot 3 = 1.5 \cdot 10^{6}$ This corresponds to 1.5MBs per image. We wish to make our objects as small as possible so that they travel through the network and memory quickly.
There are multiple paths to achieve this:
numpyarray $\rightarrow$ pickled object $\rightarrow$lzma-ed object $\rightarrow$ Binary field in mongodbnumpyarray $\rightarrow$ compressed/modifiednumpyarray $\rightarrow$ pickled object $\rightarrow$ Binary field inmongodbnumpyarray $\rightarrow$ compressed/modifiednumpyarray $\rightarrow$ pickled object $\rightarrow$lzma-ed object $\rightarrow$ Binary field inmongodb
In the first route, the pickled array is compressed. These images compress really well, for there are many similar byte sequences corresponding to identical colours. The drawback is that the image has to be manipulated by lzma which can be slow.
Following the second path, one modifies the numpy array to an other one of considerably smaller size whilst retaining all the spatial information. This array is then pickled. In this case the unpickled object can be used by numpy straightaway. The drawback that the custom compressor/decompressor has to be used, and the user has to be warned accordingly.
The third one might be a slow overkill.
A minimalistic compressor–decompressor pair is implemented below. compress_image2 looks for horizontal sequences of indetical colours. (Notwithstanding there is much room for improvement, we choose not delve too deep into optimising these utilities at this stage.
@nb.jit(nopython = True)
def compress_image2(X):
"""
Creates a coordinate sparse array representation of an RGB image.
Parameters:
X (np.ndarray[height, width, 3] of uint8) : RGB image.
Returns:
compressed (np.ndarray[n_regions, 7]) : compressed image, where
row[0:4] : row start, column start, row end, column end
row[4:] : R, G, B codes of the region of constant colour.
"""
ir, jr, _ = X.shape
coo = []
r_s, c_s = 0, 0
c_old = X[0, 0]
for i in range(ir):
for j in range(0, jr):
# append end of color region and colour
if X[i, j, 0] != c_old[0] or \
X[i, j, 1] != c_old[1] or \
X[i, j, 2] != c_old[2]:
if j == 0:
coo.append([r_s, c_s, i - 1, jr, c_old[0], c_old[1], c_old[2]])
else:
coo.append([r_s, c_s, i, j, c_old[0], c_old[1], c_old[2]])
c_old = X[i, j]
r_s, c_s = i, j
coo.append([r_s, c_s, ir - 1, jr, c_old[0], c_old[1], c_old[2]])
compressed = np.array(coo, dtype = np.uint16)
return compressed
The decompressor, decompress_image2 fills subsequent regions with colours.
@nb.jit(nopython = True)
def decompress_image2(X):
"""
Creates a coordinate sparse array representation of an RGB image.
Parameters:
X (np.ndarray[n_regions, 7]) : compressed image, where
row[0:4] : row start, column start, row end, column end
row[4:] : R, G, B codes of the region of constant colour.
Returns:
decompressed (np.ndarray[height, width, 3] of uint8) : RGB image.
"""
h = np.int64(X[-1, 2] + 1)
v = np.int64(X[-1, 3])
decompressed = np.zeros((h, v, 3), dtype = np.uint8)
for k in range(X.shape[0]):
r_s = X[k,0]
c_s = X[k,1]
r_e = X[k,2]
c_e = X[k,3]
if r_s == r_e:
decompressed[r_s, c_s : c_e] = X[k, 4:]
elif r_s + 1 == r_e:
decompressed[r_s, c_s :] = X[k, 4:]
decompressed[r_e, : c_e] = X[k, 4:]
else:
decompressed[r_s, c_s :] = X[k, 4:]
decompressed[r_s + 1 : r_e, :] = X[k, 4:]
decompressed[r_e, : c_e] = X[k, 4:]
return decompressed
The compression ratios and execution times are compared on a randomly selected set of fifty images. The execution time includes
- pickling
- compression
- extraction
- unpickling for both routes.
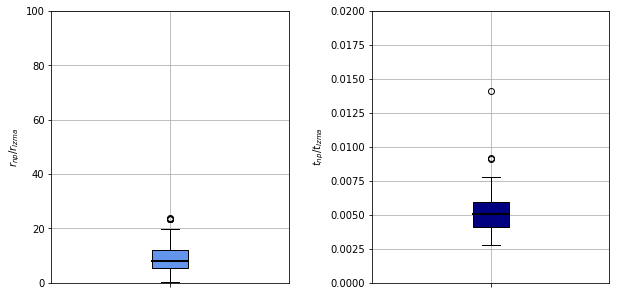
The lzma achieves ten to fifteen times better compression ratio, for it has a global view of the bytes that encode the object. The compactness incurs a high cost in time. It is hundred times slower than the full numpy cycle. The rough average timings are 100 ms and 1 ms per image via the lmza and numpy paths, respectively.
As to which one to use, depends on the query time as a function the size of the compressed and pickled object.
Flag data structure
The following steps should be executed to obtain a dictionary template of the “flag” document:
- choose relevant fields from raw country documents
- load image from local store
- clean image
- compress and pickle canvas
- generate other statistics fields
- collate to a dictionary
Steps 1.–4. are done by the modestly interesting function create_flag_object_dict which is shown in its full g(l)ory below. The ImageScalerCleaner removes spurious colours due to finite resolution from a flag. Its construction and characteristics were discussed in this blog post the source code can be located in this folder.
def create_flag_document_dict(path, code):
"""
Reads, cleans compresses a flag and collates with other relevant attributes.
Parameters:
path (str) : local path to the image
code (str) : two letter country code
Returns:
document_dict ({:}) : dictionary of flag attributes.
"""
# create flag bytestring
image = imread(path)
cleaner = ImageScalerCleaner()
image_cleaned = cleaner.clean(image)
image_bytes = Binary(pickle.dumps(compress_image2(image_cleaned)))
# get dimensions
height, width = image.shape[:2]
# get colour histogram
stringify = lambda x: "-".join([str(y) for y in x])
colours = {stringify(colour) : weight
for colour, weight in zip(cleaner.histo.colours, cleaner.histo.counts)}
data = {
"canvas" : image_bytes,
"dimensions" : {"height" : height, "width" : width},
"colours" : colours
}
# collate to all fields
document_dict = {
"code" : code,
"data" : data
}
return document_dict
Country document
The fields of the country document are populated from the query result. The flag field is omitted, for it will be added once the ids of the flag documents are known.
def create_country_document_dict(fields):
"""
Creates a dictionary representing a flag document
Parameters:
fields ({:}) : raw country attributes as a dictionary
Returns:
document_dict ({:}) : dictionary containing the relevant attributes of a certain country
"""
# copy accross relevant fields
data_field_names = ('name', 'continent', 'founded', 'independent', 'neighbours', 'religion')
data = {field_name : fields[field_name] for field_name in data_field_names}
document_dict = {
"code" : fields['code'],
'data' : data,
}
return document_dict
Creating the collections
Flags
All flag dictionaries are created in a single pass over the returned elements from querying the raw_countries collection.
cl_raw_countries = db_flag["raw_countries"]
flag_dicts = [create_flag_document_dict(x['path'], x['code']) for x in cl_raw_countries.find({})]
From these items the flags collection is created. If there is an earlier version it will be dropped.
if 'flags' in db_flag.list_collection_names():
db_flag.drop_collection('flags')
cl_flag = db_flag.create_collection('flags')
cl_flag.insert_many(flag_dicts)
As a test, we retrieve the flag of Algeria. As expected, there is only one matching document.(Please note, the bytestring is truncated.)
flags = cl_flag.find({'code' : 'DZ'})
for flag in flags:
print('code :', flag['code'])
print('data : colours :', flag['data']['colours'])
print('data : dimensions :', flag['data']['dimensions'])
print('data : canvas : ', flag['data']['canvas'][:100])
code : DZ
data : colours : {'255-255-255': 0.4793593513320859, '0-98-51': 0.4606121357925688, '210-16-52': 0.060028512875345275}
data : dimensions : {'height': 387, 'width': 580}
data : canvas : b'\x80\x03cnumpy.core.multiarray\n_reconstruct\nq\x00cnumpy\nndarray\nq\x01K\x00\x85q\x02C\x01bq\x03\x87q\x04Rq\x05(K\x01M\xa0\x05K\x07\x86q\x06cnumpy\ndtype\nq\x07X'
Next, we print all flags whose canvases contain pure red:
for flag in cl_flag.find({'data.colours.255-0-0' : {'$exists' : True} }, {'code' : 1}):
print(flag)
{'_id': ObjectId('5cb06a2c351ab08028a97afb'), 'code': 'AU'}
{'_id': ObjectId('5cb06a2c351ab08028a97b11'), 'code': 'CA'}
{'_id': ObjectId('5cb06a2c351ab08028a97b1b'), 'code': 'HR'}
{'_id': ObjectId('5cb06a2c351ab08028a97b30'), 'code': 'GE'}
{'_id': ObjectId('5cb06a2c351ab08028a97b7b'), 'code': 'PT'}
{'_id': ObjectId('5cb06a2c351ab08028a97b9a'), 'code': 'CH'}
{'_id': ObjectId('5cb06a2c351ab08028a97baa'), 'code': 'AE'}
Countries
A list of dictionaries are created from the query on the raw countries:
country_dicts = [create_country_document_dict(x) for x in cl_raw_countries.find({})]
The collection of countries is built in three passes:
- The prepared dictionries are inserted
- The
flagfields are populated with the ids of the related flags - The two letter codes are replaced by the country ids
if 'countries' in db_flag.list_collection_names():
db_flag.drop_collection('countries')
cl_countries = db_flag.create_collection('countries')
cl_countries.insert_many(country_dicts)
Let us display the record of South Africa:
next(cl_countries.find({'code' : 'ZA'}))
{'_id': ObjectId('5cb06a2c351ab08028a97c55'),
'code': 'ZA',
'data': {'name': 'SOUTH AFRICA',
'continent': 'AFRICA',
'founded': 1910,
'independent': 1910,
'neighbours': ['BW', 'LS', 'MZ', 'NA', 'SZ', 'ZW'],
'religion': 'CHR'}}
We then search for all countries that became independent between 1989 an 1993. We are expecting to see states from the reorganised Eastern Block, which we do.
for country in cl_countries.find({'data.independent' : {'$gt' : 1988, '$lt' : 1994}}, {'code' : 1}):
print(country)
{'_id': ObjectId('5cb06a2c351ab08028a97bbe'), 'code': 'AM'}
{'_id': ObjectId('5cb06a2c351ab08028a97bc1'), 'code': 'AZ'}
{'_id': ObjectId('5cb06a2c351ab08028a97bc6'), 'code': 'BY'}
{'_id': ObjectId('5cb06a2c351ab08028a97bcc'), 'code': 'BA'}
{'_id': ObjectId('5cb06a2c351ab08028a97bdf'), 'code': 'HR'}
{'_id': ObjectId('5cb06a2c351ab08028a97be2'), 'code': 'CZ'}
{'_id': ObjectId('5cb06a2c351ab08028a97bec'), 'code': 'ER'}
{'_id': ObjectId('5cb06a2c351ab08028a97bed'), 'code': 'EE'}
{'_id': ObjectId('5cb06a2c351ab08028a97bf4'), 'code': 'GE'}
{'_id': ObjectId('5cb06a2c351ab08028a97bf5'), 'code': 'DE'}
{'_id': ObjectId('5cb06a2c351ab08028a97c0b'), 'code': 'KZ'}
{'_id': ObjectId('5cb06a2c351ab08028a97c0f'), 'code': 'KG'}
{'_id': ObjectId('5cb06a2c351ab08028a97c11'), 'code': 'LV'}
{'_id': ObjectId('5cb06a2c351ab08028a97c17'), 'code': 'LT'}
{'_id': ObjectId('5cb06a2c351ab08028a97c19'), 'code': 'MK'}
{'_id': ObjectId('5cb06a2c351ab08028a97c25'), 'code': 'MD'}
{'_id': ObjectId('5cb06a2c351ab08028a97c2c'), 'code': 'NA'}
{'_id': ObjectId('5cb06a2c351ab08028a97c43'), 'code': 'RU'}
{'_id': ObjectId('5cb06a2c351ab08028a97c51'), 'code': 'SK'}
{'_id': ObjectId('5cb06a2c351ab08028a97c52'), 'code': 'SI'}
{'_id': ObjectId('5cb06a2c351ab08028a97c61'), 'code': 'TJ'}
{'_id': ObjectId('5cb06a2c351ab08028a97c6a'), 'code': 'TM'}
{'_id': ObjectId('5cb06a2c351ab08028a97c6d'), 'code': 'UA'}
{'_id': ObjectId('5cb06a2c351ab08028a97c72'), 'code': 'UZ'}
In the next step the ids of the associated flag documents are inserted. Since the two letter code is included in each flag document they can easily be found.
for flag in db_flag.flags.find():
db_flag.countries.update_one(
{'code': flag['code'] },
{'$set': {'flag': flag['_id']}}
)
The each document now contains the id of the associated flag:
db_flag.countries.find_one({'code' : 'ZA'})
{'_id': ObjectId('5cb06a2c351ab08028a97c55'),
'code': 'ZA',
'data': {'name': 'SOUTH AFRICA',
'continent': 'AFRICA',
'founded': 1910,
'independent': 1910,
'neighbours': ['BW', 'LS', 'MZ', 'NA', 'SZ', 'ZW'],
'religion': 'CHR'},
'flag': ObjectId('5cb06a2c351ab08028a97b91')}
Finally, the two letter codes in the neighbour list are replaced by the id-s of the countries they represent:
for country in db_flag.countries.find():
# find ids of neighbouring countries
ids = [db_flag.countries.find_one({'code' : code})['_id'] for code in country['data']['neighbours']]
# update country
cid = country['_id']
db_flag.countries.update_one(
{'_id' : cid},
{'$set' : {'data.neighbours' : ids}}
)
The updated field therefore lists the object ids of the neighbouring countries
db_flag.countries.find_one({'code' : 'FR'})
{'_id': ObjectId('5cb06a2c351ab08028a97bf1'),
'code': 'FR',
'data': {'name': 'FRANCE',
'continent': 'EUROPE',
'founded': 9999,
'independent': 1944,
'neighbours': [ObjectId('5cb06a2c351ab08028a97c6f'),
ObjectId('5cb06a2c351ab08028a97bba'),
ObjectId('5cb06a2c351ab08028a97bc7'),
ObjectId('5cb06a2c351ab08028a97bf5'),
ObjectId('5cb06a2c351ab08028a97c07'),
ObjectId('5cb06a2c351ab08028a97c18'),
ObjectId('5cb06a2c351ab08028a97c26'),
ObjectId('5cb06a2c351ab08028a97c58'),
ObjectId('5cb06a2c351ab08028a97c5e')],
'religion': 'CHR'},
'flag': ObjectId('5cb06a2c351ab08028a97b2d')}
Summary
A mongoDB database has been created in which attributes of countries and their flags are stored. The countries and their flags are stored in separate collection, therefore keeping the former’s size small, and the latter one concise.